Credit Risk Modeling with Transformers: A Literature Review and My Experimentation


1. Babaei and Giudici (2024) - "GPT Classifications, with Application to Credit Lending"
Technique: Prompt-engineering
Focus:
Application of GPT models in binary classification for credit scoring.
Comparison with traditional machine learning models like logistic regression.
Key Points:
a. Data Preparation and Input for Transformer Models:
The prompt sent to the model for prediction includes four key components: Task Definition, Examples, Variable Descriptions, and Request

b. Comparison with Traditional Models:
Data Efficiency: The paper demonstrates that GPT models can achieve comparable performance to logistic regression models with significantly fewer data points. This efficiency is attributed to the model's pre-trained knowledge and its ability to leverage contextual examples within prompts.
Performance Metrics: GPT models showed robust performance in binary classification tasks, though logistic regression slightly outperformed GPT models in their study. However, the gap in performance narrows when GPT is supplemented with well-designed prompts and a small set of training examples.
Application Accessibility: One of the major advantages of GPT models is their accessibility to non-expert users. By using natural language prompts, even individuals without extensive data science knowledge can perform complex tasks like credit scoring.
c. Robustness and Bias:
The authors discuss how GPT models trained on large datasets can handle a wide range of scenarios, capturing both general and domain-specific knowledge. However, they also caution about the potential for these models to propagate biases present in their training data.
2. Deldjoo (2023) - "Fairness of ChatGPT and the Role of Explainable-Guided Prompts"
Technique: Prompt-engineering
Focus:
Evaluation of GPT models in credit risk assessment.
Analysis of model fairness and the impact of explainable-guided prompts.
Key Points:
a. Data Preparation and Input for Transformer Models:
The prompt being sent to the model for prediction includes task instruction, examples, attribute description, domain knowledge integration and final task question.

b. Comparison with Traditional Models:
Minimizing False Positives: GPT models were particularly effective at minimizing false positives, which is crucial in credit risk assessment to avoid granting credit to high-risk individuals.
Fairness and Bias Mitigation: Through prompt engineering, GPT models can be tuned to be more fair and less biased than traditional models. The study shows that these models, with the right prompts, can achieve performance comparable to classical models like random forests and logistic regression.
Lower Data Requirements: Traditional models often require extensive training data to perform well. In contrast, GPT models, when supplemented with domain-specific examples, can achieve similar performance with significantly fewer training examples.
c. Challenges and Opportunities:
Bias and Fairness: The paper discusses how the vast amount of internet data used to train GPT models can introduce societal biases. The authors highlight the role of prompt engineering in mitigating these biases and enhancing fairness in the model's outputs.
Comparative Performance: Despite their smaller data footprint, GPT models were competitive with traditional models in the credit risk assessment tasks, highlighting their potential efficiency and adaptability.
3. Feng et al. (2024) - "Empowering Many, Biasing a Few: Generalist Credit Scoring through Large Language Models"
Technique: Fine-tuning
Focus:
Examination of GPT models in credit scoring applications.
Analysis of biases and the robustness of large language models compared to traditional models.
Key Points:
a. Data Preparation and Input for Transformer Models:
Table-based instruction is designed for data containing too many meaningless symbols, while description-based instruction transforms the table into natural language.

b. Comparison with Traditional Models:
Bias and Robustness: The paper thoroughly investigates the biases present in GPT models and compares them to traditional models like logistic regression and decision trees. They find that while GPT models can capture a wide range of knowledge, they also risk amplifying biases inherent in their training data.
Performance Across Different Tasks: GPT models were found to be robust and adaptable across various financial evaluation tasks. In some cases, they outperformed traditional models in capturing complex patterns and relationships within the data.
Efficiency and Adaptability: Traditional models like logistic regression were noted for their simplicity and interpretability. However, GPT models' ability to adapt and perform well with fewer training examples makes them a powerful alternative, especially when domain-specific knowledge is embedded in prompts.
c. Future Directions:
Mitigating Biases: The authors stress the importance of developing techniques to mitigate biases in GPT models. They propose ongoing research into improving prompt designs and incorporating fairness-aware mechanisms to ensure more equitable model outcomes.
Generalization Abilities: GPT models’ strong generalization capabilities are highlighted as a key advantage over traditional models, particularly in tasks involving diverse and complex data.
4. Yin et al. (2023) - "FinPT: Financial Risk Prediction with Profile Tuning"
Technique: Fine-tuning
Focus:
Application of transformer models in financial risk prediction.
Introduction of profile tuning techniques to enhance model performance.
Key Points:
a. Data Preparation and Input for Transformer Models:
The author claimed the technique as profile tuning. It is similar to converting a table to a natural language.
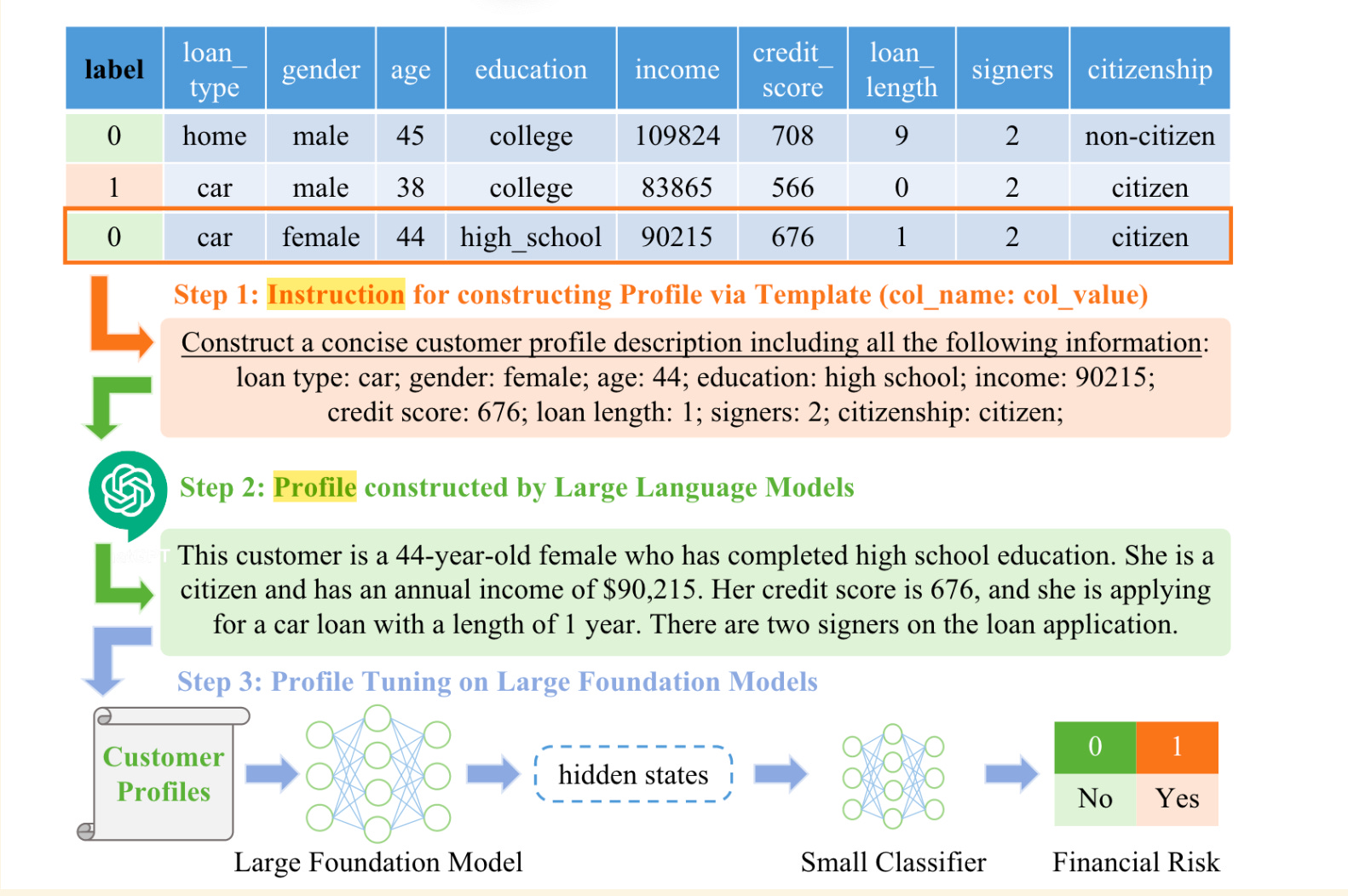
b. Comparison with Traditional Models:
Performance in Financial Risk Prediction: Transformer models, particularly those using profile tuning, outperformed traditional models in predicting financial risks. The study found that these models could better capture complex patterns in the data, leading to more accurate predictions.
Adaptability and Scalability: Unlike traditional models, which often require significant retraining to adapt to new data, transformer models can leverage their pre-trained knowledge and adapt more readily to new financial contexts with minimal additional training.
Bias and Fairness: The study also explores the potential for bias in transformer models, noting that while they can generalize well across diverse datasets, they also risk propagating biases from their training data. The authors advocate for the integration of fairness-aware techniques in model tuning to address these concerns.
c. Practical Implications:
Efficiency in Data Utilization: Traditional models typically need extensive data preprocessing and large amounts of labeled data to achieve high performance. In contrast, transformer models, with profile tuning, require less labeled data and can process diverse data types more efficiently.
Enhanced Decision-Making: The ability of transformers to integrate and analyze complex financial data makes them superior in scenarios where detailed risk assessments are required. Their advanced capabilities in understanding and predicting financial risks provide a significant advantage over traditional models.
Summary
Each paper provides unique insights into the preparation and application of transformer models like GPT in various contexts, particularly in financial risk and credit scoring tasks. The comparisons with traditional models highlight the transformative potential of transformers in handling complex, unstructured data with fewer training examples and their adaptability across different domains. However, challenges related to bias, data requirements, and model complexity remain critical areas for ongoing research and development.
Finally, my trial of using BertSequenceClassification achieved an AUC of 73% on the evaluation set without fully maximising the token size and all data.